Es war ein deutliches Signal: Während die meisten heimischen Verlage verbissen um ein Leistungsschutzrecht kämpften, machte Zeit Online das genaue Gegenteil: Nach dem Vorbild einiger amerkanischer und englischer Zeitungshäuser veröffentlichte der Verlag eine API und gab die Hoheit über Teile der Inhalte damit in die Hände der Entwickler-Community. Ein Überblick über Medienhäuser, die den Schritt zu mehr Offenheit gewagt haben.

Mehr als 8.000 APIs waren bei programmableweb im November letzten Jahres gelistet, inzwischen dürfte die 9.000-Marke überschritten sein. Es gibt kaum ein namhaftes Startup, das nicht irgendwann eine API anbietet und es gibt Unternehmen wie Google, die gleich schon mit der Auslieferung von Produkten wie Glass eine dazugehörige API veröffentlichen. APIs sind schick, denn APIs stehen für Offenheit, Austausch und den Open-Data-Trend. Doch APIs sind auch Business: Es ist kaum vorstellbar, dass Unternehmen wie Twitter oder Facebook ohne ihre Programmierschnittstellen zu dem geworden wären, was sie heute sind.
Offenheit bei etablierten, von Geschäftsgeheimnis und Konkurrenzkampf geprägten Unternehmen ist allerdings ein etwas schwierigeres Thema, auch wenn Offenheit die Bindung von externer Innovationskraft verspricht. Ganz besonders dürfte das für die etablierte Medienbranche gelten, die vorrangig mit Wissen und Informationen ihr Geschäft betreibt.
Zu Recht? Das ist in der Außenperspektive schwer zu beurteilen, zumal ja auch Unternehmen wie Twitter inzwischen zunehmend restriktiv mit ihrer API-Strategie umgehen. Allerdings gibt es unter den jungen Startups auch im Buch- und Verlags-Bereich sehr viele Vertreter, die mit einer Schnittstelle ins Rennen gehen. Und selbst bei traditionellen Unternehmen der Medienbranche haben einige den Schritt in die Offenheit gewagt und dadurch scheinbar keinen großen Schaden erlitten.
Was war jetzt noch gleich eine API?
APIs sind „Application Programming Interfaces“ und der Name sagt eigentlich schon alles: Es sind Programmier-Schnittstellen, die die Kommunikation zwischen zwei (Web-)Applikationen ermöglichen. Wenn man sich zum Beispiel bei Pinterest über den Facebook-Button anmeldet oder registriert, dann tauscht Pinterest die Daten zur Authentifizierung mit Facebook über die Facebook-API aus. Wenn man dann noch angezeigt bekommt, welcher Facebook-Freund jetzt was und wie bei Pinterest macht, werden auch diese Informationen über die Facebook-(Graph-)API bezogen. Letztlich ist die API eine Konvention, wie und in welchem Format Daten abgerufen und gesendet werden können, und je nach Ausgestaltung der API sind das mal mehr und mal weniger umfangreiche Daten. Am häufigsten geschieht der Datenaustausch bei modernen APIs im JSON-Format, oft ist auch das XML-Format anzutreffen, seltener speziellere Formate wie RDF und andere.
Wer sich für die technischen Details interessiert und alles genauer wissen will, der kann sich mal bei Codecademy den API-Track anschauen.
APIs bei internationalen Verlagen und Medienhäusern
Unter den englischsprachigen Presseverlagen, News-Organisationen und Rundfunk-Anbietern gibt es mindestens acht bekannte Häuser, die Programmier-Schnittstellen anbieten:
- BBC: Vermutlich war die BBC das erste große traditionelle Medienunternehmen, das eine API veröffentlicht hat. Das war im Jahr 2006. Heute gibt es ein eigenes Developer Center mit mehreren APIs.
- National Public Radion (NPR): NPR ist eine lose Kooperation von amerikanischen Rundfunksendern, die im Sommer 2008 mit ihrer API vermutlich den Startschuss in den USA gegeben hat. NPR bietet heute drei APIs an: Eine für Content, eine für Transciptions und einen Station Finder.
- New York Times: Die New York Times war im Oktober 2008 der Vorreiter in Sachen API bei Zeitungs-Verlagen. Inzwischen betreibt der Verlag eine umfangreiche Developer-Plattform mit insgesamt 15 APIs, die von „Articles“ bis „Geography“ reichen.
- Guardian: Im März 2009 folgte der englische Guardian, der inzwischen als Speerspitze des Data-Journalism gilt. Kronjuwel der Guardian Open Plattform ist die Content-API.
- USA-Today: Die amerikanische Zeitung ist im Oktober 2010 mit seinem Developer Network an den Start gegangen. Die Plattform bietet Zugriff auf 8 Content-APIs von „Articles“ bis „Sports Salaries“.
- Washington Post: Auch die Washington Post bietet auf ihrem Developer Portal zwei APIs an: Die Trovi-API (Politiker-Transcripte und Statements) und die White House Visitors API. Bis Ende 2012 hatte die Zeitung anlässlich der Wahl auch noch eine Campaign Finance API angeboten.
- Thomson Reuters: Reuters hatte bereits im Sommer 2008 eine Content-API unter dem Namen Spotlight gelauncht und gehörte damit zu den ersten API-Anbietern unter den etablierten Medien-Unternehmen. Der Service wurde allerdings offensichtlich eingestellt und heute bietet Reuters mehrere APIs an, die sich thematisch im Bereich Pharma, Chemie und Finance bewegen.
- Associated Press: Die amerikanische Nachrichtenagentur AP hat 2012 eine Content- und Metadaten-API online gestellt.
- Huffington Post: Ohne viel Aufmerksamkeit zu erregen hat die Huffington Post im August 2012 mit der Pollster-API eine Schnittstelle veröffentlicht, über die politische Meinungsumfragen seit 2004 abgerufen werden können.
Einige Buch-Verlage bieten inzwischen ebenfalls offene Schnittstellen an, auch wenn sich meistens nur bibliographische Daten abrufen lassen. Zu den Verlagen zählen:
- Elsevier: Der weltgrößte Wissenschaftsverlag Elsevier hat mal eine Article-API betrieben, diese allerdings wieder eingestellt. Es existiert jedoch nach wie vor ein Developer-Portal, auf dem mehrere, teilweise nur für Subscriber zugängliche APIs vorgestellt werden.
- HarperCollins: Der Buch-Publisher aus den USA bietet eine Open Book API. Das ist der einzige belletristische Verlag in dieser API-Liste.
- LexisNexis: Das Angebot des juristischen Verlags LexisNexis ist etwas unübersichtlich, das Haus bietet aber mindestens APIs für Libraries, für den Martindale und für das Lawyer-Verzeichnis an.
- O’Reilly: Der bekannte IT-Verlag bietet das O’Reilly Public Metadate Interface an, über das im RDF-Format diverse Informationen zu den Verlagstiteln abgerufen werden können.
- Pearson: Der Verlag hinter Penguin Books und der Financial Times hat eine komplette Developer Plattform aufgesetzt, auf der aktuell zehn verschiedene APIs angeboten werden.
- Random House: Der Verlag Random House stammt ursprünglich aus den USA, bildet heute jedoch die Dachmarke aller Buchverlage von Bertelsmann. Random-House bietet eine API zu Autoren, Events, Titeln und Works an.
APIs bei deutschen Verlagen
Den größten Hype in Sachen APIs hat bislang wohl Zeit Online produziert, als der Verlag Ende letzten Jahres eine offene Content-API vorgestellt und parallel im Berliner Sitz nahe des Potsdamer Platzes einen Entwickler-Workshop zu ihrer API veranstaltetet hat. Damit war die Zeit der erste große Zeitungsverlag in Deutschland, der eine Content-API zur Verfügung gestellt hat. Der erste Verlag in Deutschland generell war die Zeit allerdings nicht.
Springer Science Business
Der Springer-Verlag ist nach Elsevier der weltweit zweitgrößte Wissenschaftsverlag und hat natürlich nichts mit Axel Springer zu tun. Nach rechtlichem Sitz gehört der Verlag zwar zu Luxemburg (durch die Fusion mit dem Wolters-Verlag vor ein paar Jahren), allerdings befindet sich der operative Hauptsitz nach wie vor in Berlin.
Der Verlag hat 2010 ein eigenes API-Portal aufgesetzt, auf dem drei Schnittstellen angeboten werden:
- Metadata API – Über die Schnittstelle sind Metadaten zu 5 Millionen Online-Dokumenten aus Zeitschriften, Buchkapiteln und Laborprotokollen abrufbar.
- Images API – Erreichbar sind Bilder und Bildlegenden aus 300.000 Bildern der Datenbank SpringerImages.
- Open Access API – Über die API werden Metadaten, Inhalte aus Volltexten und Bilder aus 80.000 Open Access-Artikeln von BioMed Central und SpringerOpen zur Verfügung gestellt.
Springer hat sein API-Portal aktiv beworben und 2011 und 2012 jeweils einen Entwickler-Wettbewerb veranstaltet. Im ersten Wettbewerb ging Springer Quotes als Sieger auf das Treppchen. Im zweiten Wettbewerb konnte sich Kleenk durchsetzen, eine Plattform zur Förderung der Verlinkung und Zitierung eigener Forschungsarbeiten und anderer Publikationen.

Kleenk schien eine zeitlang echte Ambitionen als Startup zu haben und kooperierte zwischenzeitlich auch mit Mendeley (die ja kürzlich von Springers Haupt-Konkurrenten Elsevier aufgekauft wurden). Allerdings hat Kleenk schon Mitte 2012 seine Social-Media-Kommunikation eingestellt und auch eine Registrierung scheint nicht mehr möglich zu sein. Schon zuvor hatte Springer mit dem ähnlich gelagerten (Bookmarking-)Service CiteULike kooperiert, um die es dann allerdings auch ruhiger geworden ist. Für 2013 wurde bislang von Springer kein neuer Wettbewerb ausgerufen, das Forum existiert noch, der Entwickler-Blog allerdings nicht.
Programmableweb zeigte sich von dem Ergebnis des zweiten Contests und den sechs prämierten Anwendungen aller Wettbewerbe beeindruckt. Bleibt die Frage, wie Springer selbst den Erfolg seiner API-Plattform einschätzt.
Zeit Online Content-API
Neben Springer Science dürfte die API von Zeit Online das ambitionierteste Projekt hierzulande sein. Die API gewährt Zugriff auf Inhalte und Metadaten aus dem Archiv der Printausgabe seit 1946 und von Zeit Online. Die Schnittstelle erlaubt ein Auslesen von Metadaten wie Autor, Schlagwörter, Serien etc. Eine Volltext-Suche ist ebenfalls möglich, ein Volltext-Zugriff aus urheberrechtlichen Gründen allerdings nicht.

Zeit online hat inzwischen 13 auf der API basierende Anwendungen gelistet und außerdem zahlreiche Tools (u.a. Anbindungen mit Rails und PHP) sowie einige Tutorials verlinkt. Dabei handelt es sich allerdings nur um eine Auswahl, denn bereits nach einem Monat gab es wohl 23 Anwendungen und über 800 Registrierungen für den API-Zugriff. Am 10. April hat der Developer-Blog dann die Veröffentlichung des API-Quellcodes auf Github bekannt gegeben.
Golem-API
Die API von Golem ist vermutlich die erste Programmier-Schnittstelle von einem deutschsprachigen Verlag: Sie existiert seit Juni 2009 und erlaubt den Zugriff auf Textinhalte, Bilder und auch Videos. Es existiert eine Dokumentation, mehrere von Golem entwickelte API-Anwendungen wie z.B. ein WordPress-Plugin sowie eine externe Anwendung für Drupal.
Süddeutsche Zeitung
Die Süddeutsche verfügt zwar über einen DataGraph, damit ist allerdings der Datenjournalismus-Bereich der Zeitung gemeint, und keine API. Allerdings betreibt die Süddeutsche noch den SZ-Zugmonitor, dessen Daten auch über eine API zur Verfügung stehen.
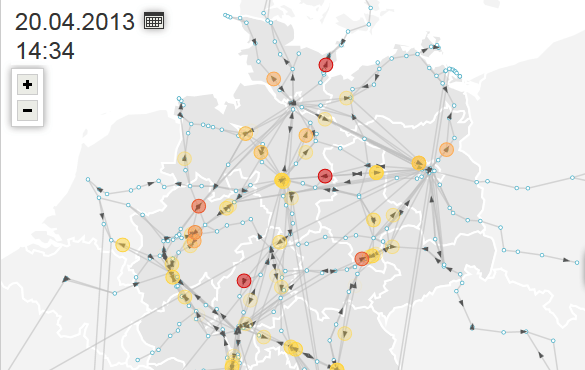
Der Zugmonitor ist allerdings kein Inhouse-Projekt der Süddeutschen, sondern wird von OpenDataCity realisiert. OpenDataCity hat auch eine Dokumentation der API veröffentlicht.
DDB
Zumindest Erwähnung finden sollte in dieser Liste auch die Deutsche Digitale Bibliothek, die mit dem Launch ihrer Online-Version Ende 2012 auch eine API-Schnittstelle für die 1. Hälfte 2013 angekündigt hat. Zwar ist die DDB kein Verlag oder Medienunternehmen, sondern eben eine Bibliothek, dennoch ist es lobenswert, dass darüber vielleicht mal Metadaten zu Verlagspublikationen einheitlich abrufbar sein könnten. Ein Vorbild könnte die Open Library sein, die Informationen zu Büchern sammelt und per API zugänglich macht.
Fazit – Was bringen APIs am Ende?
Die Diskussion über APIs bei Medienhäusern ist nicht neu: In der hiesigen Blogszene hat zum Beispiel Martin Weigert APIs für die Öffentlich-Rechtlichen oder für Zeitungen gefordert, Leander Wattig hatte vor dem Hintergrund des Springer-Wettbewerbs für mehr APIs und Hackathons bei Verlagen geworben, ganz aktuell hat Zeit Online selbst die Bedeutung von APIs als Werkzeug für Journalisten herausgestellt. In der englischsprachigen Welt haben sich Matthiew Ingram und viele andere zu dem Thema geäußert, und gerade im Buch-Bereich scheint die Diskussion um APIs 2013 wieder an Fahrt aufzunehmen: Im Zuge der Tools of Change for Publishing Conference von O’Reilly haben unter anderem Hugh McGuire und Edward Nawotka ausführliche Plädoyers für APIs im Buch-Publishing verfasst. Eines der sinnfälligsten Beispiele für neue Anwendungen, die mit APIs (leichter) möglich wären, ist das US-Startup Small Demons, das Bücher über die darin enthaltenen Peronen, Handlungsorte und Dinge vernetzt (die Infos werden aktuell jedoch nicht über APIs, sondern aus den EPUB-Versionen extrahiert).
Aktuell gehen die Verlage zumindest in Deutschland mit dem Leistungschutzrecht in die entgegengesetzte Richtung und plädieren zum großen Teil eher für eine Abschottung als für eine Öffnung. Man kann sich vorstellen, dass der Ruf nach Offenheit und APIs in den Führungsebenen der Medienhäuser derzeit auf nicht allzu fruchtbaren Boden fällt, und das würde vermutlich auch ohne Leistungsschutzrecht gelten.
Sebastian ist Senior Product Owner und Web-Entwickler. Seit 2017 entwickelt er das kleine Open Source CMS Typemill und betreibt damit unter anderem cmsstash.de, eine Fach-Publikation zum Thema Content Management Systeme.
Sehr interessanter Artikel, aber was bringt einen Verlag APIs, mehr Besucher durch Verweise?