Wenn mehr und mehr Menschen lieber ChatGPT als Google fragen, wenn sie nach Produkten suchen, müssen Unternehmen sich fragen: Wie tauchen wir hier an oberster Stelle auf? Olaf Kopp beleuchtet in seiner neuesten Kolumne die technischen Hintergründe. Dabei zeigt sich, dass es auf viele Fragen in diesem Bereich noch keine eindeutigen Antworten gibt. Bisherige Methoden der Markenbildung scheinen aber auch hier zu greifen.

Inhaltsverzeichnis
Zusammenfassung
- Generative KI wie ChatGPT und Gemini könnten die Art und Weise, wie wir Informationen suchen, verändern und Suchmaschinen-Traffic reduzieren.
- Bis 2026 wird ein Shift erwartet, bei dem KI-Chatbots und virtuelle Assistenten an Bedeutung gewinnen.
- Unternehmen müssen deshalb sicherstellen, in den Ausgaben von Sprachmodellen genannt zu werden, um relevant zu bleiben.
- Unternehmen müssen hierfür als thematisch vertrauenswürdige Quelle in KI-Systemen etabliert werden, um in den Ergebnissen aufzutauchen.
- Googles E-E-A-T-Konzept spielt eine wichtige Rolle bei der Identifizierung vertrauenswürdiger Quellen.
- Die Zukunft von SEO ist unklar, aber es wird wahrscheinlich eine Kombination aus Suchmaschinenoptimierung und LLM-Optimierung sein.
Ein Blick auf den aktuellen Shift
Anwendungen basierend auf generativer KI erobern die Welt im Sturm. Gerade für die Recherche von Informationen und die schnelle Beantwortung von Fragen könnten Dienste wie ChatGPT, Gemini und andere eine ernstzunehmende Konkurrenz für Suchmaschinen wie Google darstellen – zumindest in Teilen.
Grundsätzlich sollten wir bei dieser Betrachtung unterscheiden zwischen:
- Website-Klicks aus den Suchergebnissen (SERPs) bzw. Traffic, der verloren gehen könnte,
- sowie mögliche Verringerung der generellen Nutzung bzw. Reduktion der Suchanfragen.
Laut einer Studie von Gartner wird die Suchmaschinen-Nutzung bis 2026 um 25% zugunsten von KI-Chatbots und virtuellen Assistenten sinken.
Ich glaube persönlich zwar nicht, dass wir bis 2026 einen solchen Shift sehen werden. Dennoch glaube ich, dass zukünftige Generationen immer mehr auf KI-Chatbots für die Recherche nach Informationen und Produkten zurückgreifen werden.
Somit halte ich die 25% und mehr durchaus für realistisch, aber eher in fünf bis zehn als in zwei Jahren. Es wird eine langsamere aber stetige Entwicklung werden. Nutzergewohnheiten bleiben Gewohnheiten!
Durchaus schneller sehe ich die Verringerung des Suchmaschinen-Traffics auf Websites auf uns zukommen. Mit der Einführung von SGE (jetzt „AI Overviews“) rechne ich mit einer Reduzierung des Suchmaschinen-Traffics um durchschnittlich bis zu 20% in den ersten zwei Jahren der Einführung. Je nach Such Intention können es auch mehr oder weniger sein. Wobei ich mir sicher bin, dass die „No-Click-Suchen“ ansteigen werden, weil die generative KI bereits die Lösungen und Antworten bereitstellt.
Dadurch wird die Zeit in der Research-Journey und Customer-Journey bzw. Messy Middle kürzer.
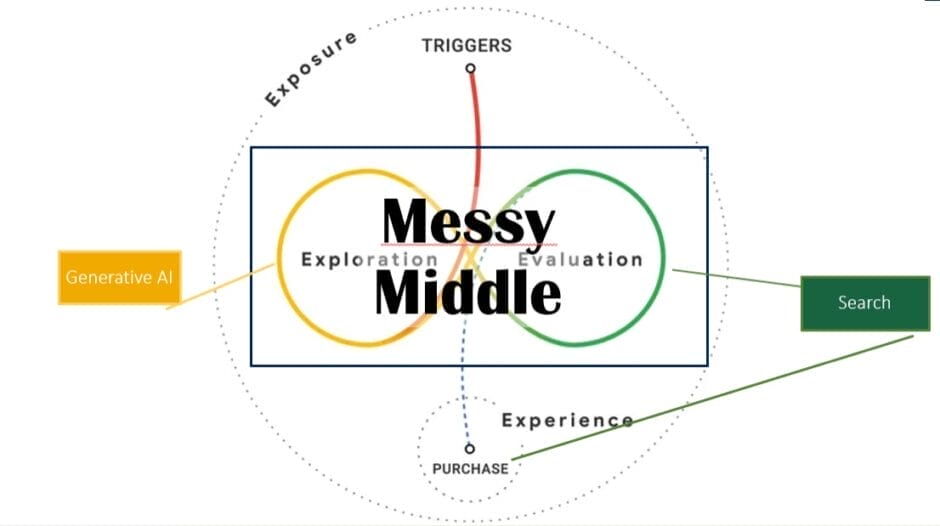
Zur Erzeugung von Awareness in der User Journey wäre es zugleich fahrlässig, nur auf Rankings in Suchmaschinen und die Klicks bzw. Website-Traffic als Folge zu setzen.
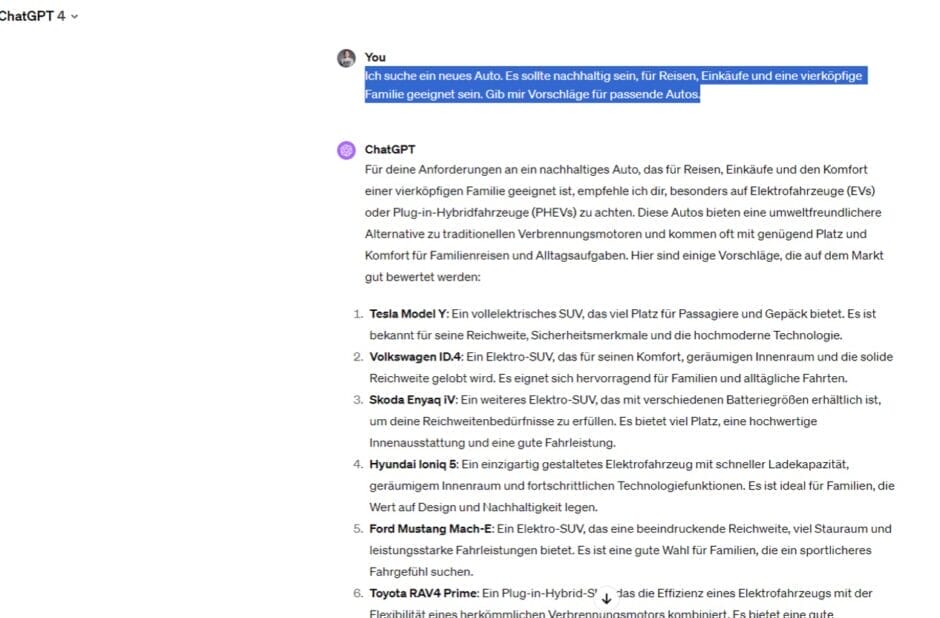
Fragt man heute ChatGPT nach einem Auto, das bestimmte Eigenschaften erfüllen soll, bekommt man konkrete Modelle vorgeschlagen:
Stellt man Gemini die gleiche Frage, werden auch bestimmte Auto-Modelle inklusive Bildern vorgeschlagen:

Interessanterweise werden beim obigen Beispiel je nach Anwendung unterschiedliche Automodelle empfohlen.
ChatGPT:
- Tesla Model Y
- Volkswagen ID.4
- Skoda Enyaq iV
- Hyundai Ioniq 5
- Ford Mustang Mach-E
- Toyota RAV 4 Prime
Copilot:
- Hyundai Ioniq 6
- Opel Mokka-e
- Fiat 500e
- VW ID.4
- Skoda Enyaq iV
Gemini:
- Toyota Prius
- Honda Clarity Plug-in-Hybrid
- Chevrolet Volt
- Tesla Model 3
Dadurch wird klar, dass je nach KI-Anwendung das unterliegende Sprachmodell (Large Language Model, LLM) anders funktioniert.
Für Unternehmen wird es zukünftig immer wichtiger, in Empfehlungen wie diesen genannt zu werden, um in ein Relevant Set möglicher Lösungen aufgenommen zu werden.
Doch warum werden genau diese Modelle von der generativen KI vorgeschlagen?
Um diese Frage ansatzweise beantworten zu können, benötigt man etwas mehr Verständnis über die technologische Funktionsweise von generativer KI bzw. LLMs.
Exkurs: Funktionsweise von LLMs
Moderne transformer-basierte LLMs wie GPT oder Gemini beruhen auf einer statistischen Analyse des gemeinsamen Auftretens von Token oder Wörtern.
Dazu werden Texte und Daten für die maschinelle Verarbeitung in Token zerlegt und mit Hilfe von Vektoren in semantischen Räumen positioniert. Vektoren können auch ganze Wörter (Word2Vec), Entitäten (Node2Vec) und Attribute sein.
In der Semantik wird der semantische Raum auch als Ontologie beschrieben. Da LLMs mehr auf Statistiken als auf echter Semantik beruhen, sind sie keine Ontologien. Allerdings kommt die KI aufgrund der hochskalierbar zu verarbeitenden Datenmengen dem semantischen Verständnis näher.
Die semantische Nähe kann durch den euklidischen Abstand oder das Kosinus Winkelmaß im semantischen Raum bestimmt werden:
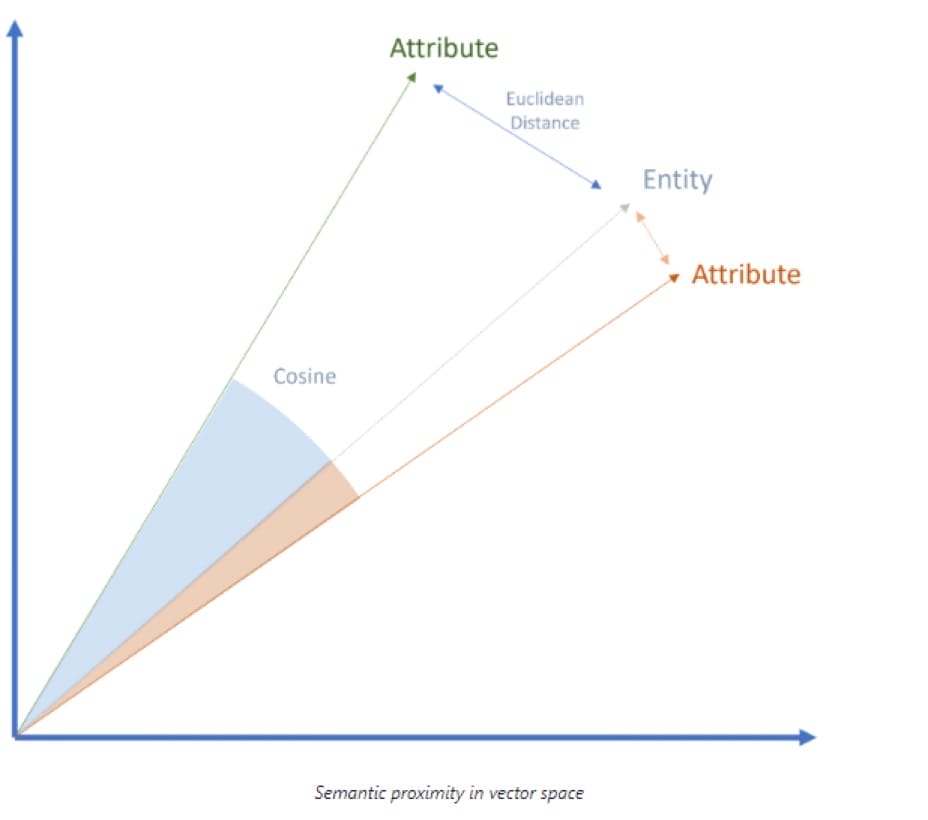
Über diesen Weg lassen sich die Beziehung zwischen Produkten und Attributen herstellen.
Den Zusammenhang ermitteln LLMs im Rahmen des Encodings über Natural Language Processing. Dadurch lassen sich in Tokens zerlegten Texte in Entitäten und Attribute unterteilen.
Über die Anzahl der Kookkurrenzen bestimmter Tokens steigt die Wahrscheinlichkeit einer Beziehung zwischen diesen Tokens.
Sprachmodelle werden initial über menschlich gelabelte Daten trainiert. Diese initialen Trainingsdaten sind Crawl-Datenbanken des Internets, andere Datenbanken, Bücher, Wikipedia … Die überwiegende Mehrheit der Daten, die zum Trainieren modernster LLMs verwendet werden, sind also Texte aus öffentlich zugänglichen Internetressourcen (z. B. der neueste „Common Crawl“-Datensatz, der Daten von mehr als drei Milliarden Seiten enthält).
Welche Quellen genau für das initiale Crawling genutzt werden, ist nicht klar.
Damit Halluzinationen reduziert werden und tieferes spezifisches Themenwissen dem LLM zugänglich wird, werden moderne LLMs zusätzlich mit Inhalten aus Domänen-spezifischen Quellen unterstützt. Dieser Prozess findet im Rahmen des Retrieval Augmented Generation (RAG) statt.
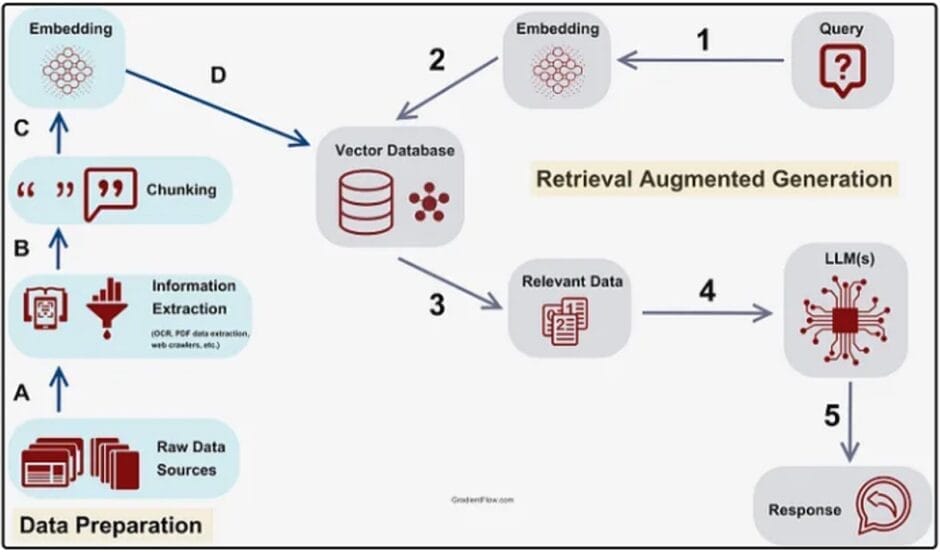
Auch Graphen-Datenbanken wie der Google Knowledge-Graph oder Shopping-Graph können im Rahmen von RAG genutzt werden, um ein bessere semantisches Verständnis zu entwickeln.
LLMO, GEO, GAIO als neue Disziplin zur Beeinflussung generativer KI
Die große Herausforderung für Unternehmen wird es sein, nicht nur in den bisher bekannten Suchmaschinen sondern auch in den Ausgaben von Sprachmodellen eine Rolle zu spielen. Sei es in Form von Quellenangaben inklusive Verlinkungen oder durch die Nennung der eigenen Marke(n) und Produkte.
Die Beeinflussung von Ausgaben von generativer KI ist ein bisher unerschlossenes Forschungsfeld. Es gibt einige Theorien und viele Namen wie z.B. Large Language Model Optimization (LLMO), Generative Engine Optimization (GEO), Generative AI Optimization (GAIO).
Belastbare Hinweise für Optimierungsansätze aus der Praxis sind bisher Mangelware. So bleibt nur die Herleitung aus dem technologischen Verständnis der LLMs.
Etablierung als thematisch vertrauenswürdige und relevante Quelle bei nicht kommerziell getriebenen Prompts
Bei nicht kauforientierten Prompts ist das wichtigste Ziel, als Quelle inklusive Verlinkung zur eigenen Website genannt zu werden.
Es wäre logisch, wenn KI-Systeme mit direkten Zugriff zu Suchmaschinen sich auf die am Besten rankenden Inhalte beim Zusammenstellen einer Antwort beziehen.
Hier ein Beispiel zum prompt: „google core update märz 2024“
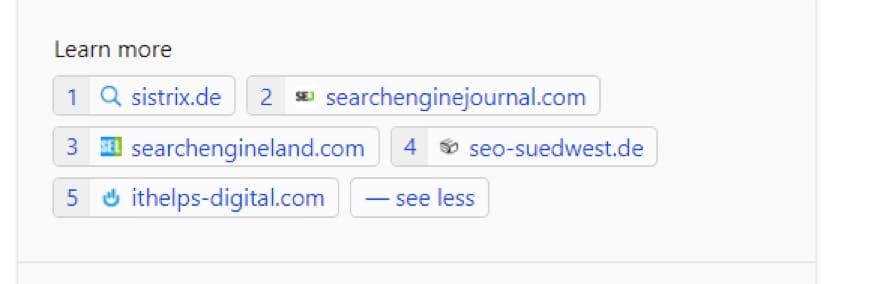
Als Quellen werden genannt:
- sistrix.de
- seo-suedwest.de
- searchengineland.com
- ithelps-digital.com
Die Ranking-Reihenfolge in den klassischen Ergebnissen ohne Videos und News zur entsprechenden Suchanfrage bei Bing in Deutschland ist wie folgt:
- sistrix.de
- contentking.de
- searchengineland.com
- Blog.google
- onlinemarketing.de
- searchenginejournal.com
- yoast.com
- …
Einige der Quellen zeigen Überschneidungen mit den Suchergebnissen, aber nicht alle.
Bei ChatGPT werden beim gleichen Prompt folgende Quellen angegeben:
- searchenginejournal.com
- searchengineland.com
- surferseo.com
Da ChatGPT auf das englischsprachige Bing zugreift habe ich mir mit der Suchanfrage „google core update march 2024“ die englischen SERPs bei Bing anzeigen lassen:
News-Box:
- Searchenginejournal.com
- Searchengineland.com
- Searchengineroundtable.com
Darunter:
- Searchengineland.com
- Blog.google
- Video-Box
- yoast.com
Auch hier sieht man einige Überschneidungen, aber ebenfalls nicht vollkommen.
Bei Gemini von Google werden derzeit keine Quellen angegeben.
Es scheinen neben den Relevanzkriterien auch andere Qualitätskriterien bei der Auswahl der Quellen zum Tragen zu kommen, die vermutlich dem E-E-A-T-Konzept von Google ähnlich sein könnten.
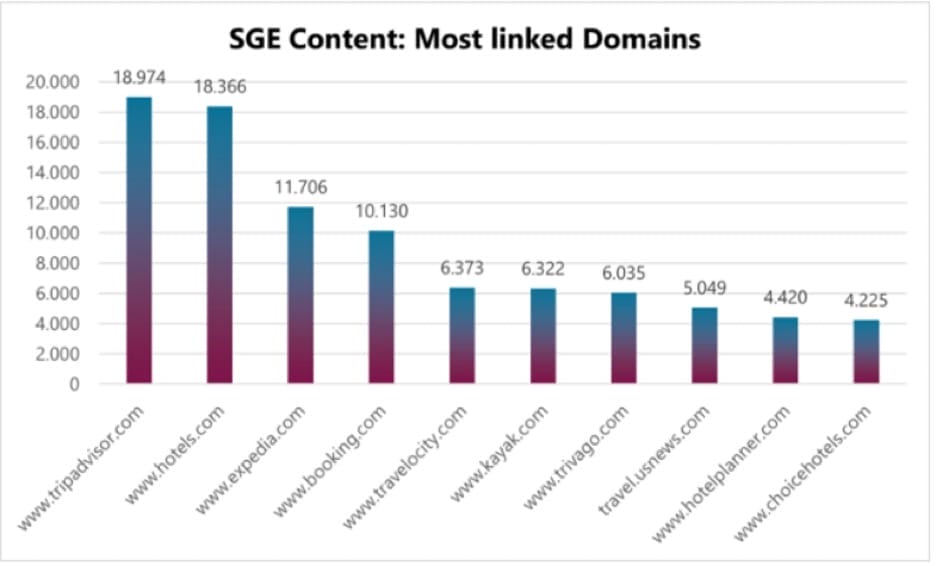
Einige Studien zu Googles SGE zeigen zudem eine hohe Korrelation zwischen bekannten Marken wie z.B. einen Studie von Peak Ace im Tourismus-Segment und eine weitere Studie von authoritas zeigt.
Peak Ace hat untersucht, welche Domains im Reise-Segment häufig aus der SGE verlinkt werden:
Authoritas hat untersucht, welche Domains generell aus der SGE verlinkt werden:
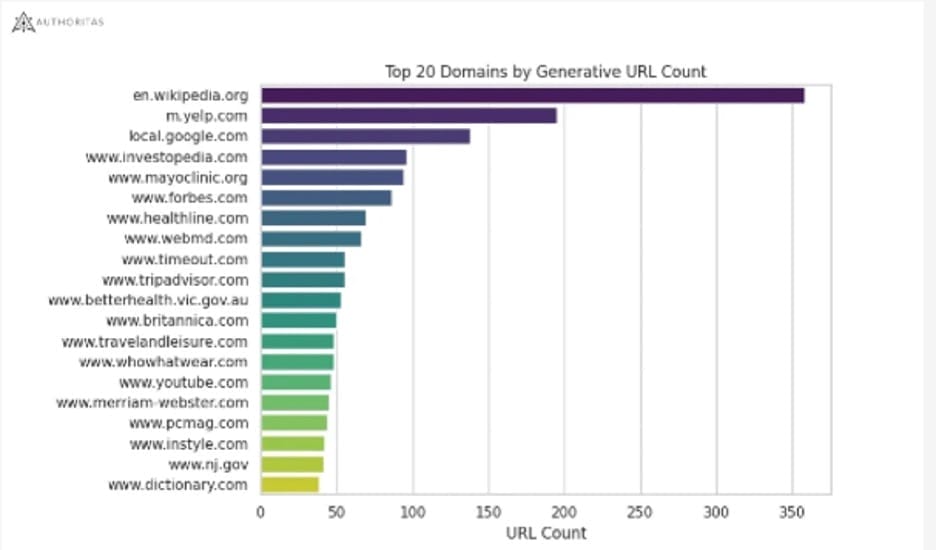
Eine Verbindung zwischen Brand-Stärke und der Auswahl der Quellen für SGE ist zu erahnen.
Digitale Marken- und Produkt-Positionierung kommerziell getriebener Prompts
Bei kauforientierten Prompts ist das wichtigste Ziel, im Rahmen der Shopping-Grids oder in der Ausgabe direkt als Marke bzw. Produkt von der KI empfohlen zu werden.
Doch wie gelingt das?
Wie immer ist auch hier ein sinnvoller Ansatz, beim Nutzer bzw. den Prompts zu beginnen. Den Nutzer und seine Bedürfnisse zu verstehen, ist wie so oft die Grundlage.
Durch Prompts lässt sich mehr Kontext mitgeben als mit den wenigen Begriffen einer üblichen Suchanfrage:

Ziel von Unternehmen sollte es daher sein, die eigenen Marken und Produkte in bestimmte Nutzerkontexte zu positionieren.
Häufige am Markt und in Prompts nachgefragte Attributsklassen (z.B. Zustand, Nutzung, Anzahl Nutzer …) können ein erster Anhaltspunkt sein, um herauszufinden, in welchen Kontexten man Marken und Produkte positioniert.
Doch wo muss diese Positionierung stattfinden?
Dafür muss man wissen, auf welche Trainingsdaten ein LLM zurückgreift. Das wiederum hängt vom jeweiligen LLM ab:
- Hat ein LLM Zugriff auf eine Suchmaschine, könnten hoch rankende Inhalte in dieser Suchmaschine eine mögliche Quelle sein.
- Renommierte (Branchen-)Verzeichnisse, (Produkt-)Datenbanken oder andere thematisch autoritäre Quellen könnten Orte für die Optimierung sein.
- Googles E-E-A-T-Konzept kann auch hier zumindest für Gemini oder die SGE eine wichtige Rolle zur Identifikation von vertrauenswürdigen Quellen als auch vertrauenswürdige Marken und Produkte spielen.
Gefällt dir dieser Artikel?
Dann bleib am Ball und trage dich jetzt ein ins „Update am Montag“. Darin: unsere neuesten Inhalte und Angebote, Tipps und Rabatte und vieles mehr. Kein Spam! Bereits knapp 1.600 Leser:innen sind dabei.
Fazit
Es bleibt abzuwarten, ob LLMO oder GAIO wirklich eine legitime Strategie zur Beeinflussung von LLMs im Hinblick auf die eigenen Ziele werden wird. Auf der Seite der Data Science gibt es Skepsis. Andere glauben an diesen Ansatz.
Wenn dies der Fall ist, müssen die folgenden Ziele erreicht werden:
- Die eigenen Medien über E-E-A-T als Quelle für Trainingsdaten etablieren.
- Generierung von Erwähnungen der Marke und Produkte in qualifizierten Medien.
- Erzeugen von Kookkurrenzen der eigenen Marke mit anderen relevanten Entitäten und Attributen in qualifizierten Medien.
- Teil der etablierten Graphen-Datenbanken wie Knowledge Graph oder Shopping Graph werden.
Die Erfolgschancen der LLM-Optimierung hängen dabei direkt mit der Größe des Marktes zusammen: Je nischenhafter ein Markt ist, desto einfacher ist es, sich als Marke in dem jeweiligen thematischen Kontext zu positionieren.
Das bedeutet, dass weniger Kookkurrenzen in den qualifizierten Medien erforderlich sind, um mit den relevanten Attributen und Entitäten in den LLMs assoziiert zu werden. Je größer der Markt ist, desto schwieriger ist dies, da viele Marktteilnehmer über große PR- und Marketingressourcen und eine lange Historie verfügen.
GAIO oder LLM-Optimierung erfordert wesentlich mehr Ressourcen als klassisches SEO, um die öffentliche Wahrnehmung zu beeinflussen.
An dieser Stelle möchte ich auf mein Konzept des Digital Authority Management hinweisen. Mehr dazu kann man in dem Artikel Authority Management: Eine neue Disziplin im Zeitalter von SGE und E-E-A-T nachlesen.
Angenommen, die LLM-Optimierung erweist sich als sinnvolle Strategie. In diesem Fall werden große Marken aufgrund ihrer PR- und Marketingressourcen in Zukunft erhebliche Vorteile bei der Suchmaschinenpositionierung und generativen KI-Ergebnissen haben.
Eine andere Perspektive ist, dass man die Suchmaschinenoptimierung wie bisher fortsetzen kann, da gut gerankte Inhalte gleichzeitig für das Training der LLMs genutzt werden. Dabei sollte man auch auf Kookkurrenzen zwischen Marken/Produkten und Attributen oder anderen Entitäten achten und darauf optimieren.
Welcher dieser Ansätze die Zukunft für SEO sein wird, ist unklar und wird sich erst zeigen, wenn SGE endgültig eingeführt wird.
Dieser Artikel gehört zu: UPLOAD Magazin 114
- Weitere Artikel aus dieser Ausgabe kostenlos auf der Website lesen ...
- Bleib auf dem Laufenden über neue Inhalte mit dem „Update am Montag“ …
Schon gewusst? Mit einem Zugang zu UPLOAD Magazin Plus oder zur Content Academy lädst du Ausgaben als PDF und E-Book herunter und hast viele weitere Vorteile!
Olaf Kopp ist Online-Marketing-Experte mit mehr als 15 Jahren Erfahrung in Google Ads, SEO und Content Marketing. Olaf Kopp ist Co-Founder, Chief Business Development Officer (CBDO) und Head of SEO & Content bei der Online Marketing Agentur Aufgesang GmbH.
Olaf Kopp ist international anerkannter Branchenexperte für semantische SEO, E-E-A-T, LLMO / Generative Engine Optimization (GEO), KI- und Suchmaschinen-Technologie, Content-Marketing und Customer Journey Management. Er ist Gründer der SEO Research Suite, der weltweit ersten Datenbank für Patente und Research Paper, die jeder SEO kennen sollte.
Als Autor schreibt er für nationale und internationale Fachmagazine wie Searchengineland, t3n, Website Boosting, Hubspot Blog, Sistrix Blog, Oncrawl Blog … . 2022 war er Top Contributor bei Search Engine Land.
Als Speaker stand er auf Bühnen der SMX, SERPConf.,, SEO Vibes, SEA/SEO World, CMCx, OMT, Digital Bash oder Campixx.
Er ist ist Host des Podcasts OM Cafe. Er ist ist Autor des Buches „Content-Marketing entlang der Customer Journey“, Co-Autor des Standardwerks „Der Online Marketing Manager“ und Mitorganisator des SEAcamp.